Daily Trend [11-29]
【1】Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
【URL】https://arxiv.org/abs/2311.15127
【Time】11-25
一、研究领域
video generation
二、研究动机
遵循 stable diffusion 的范式训练高分辨率的视频合成模型。
三、方法与技术
训练过程分三个阶段:
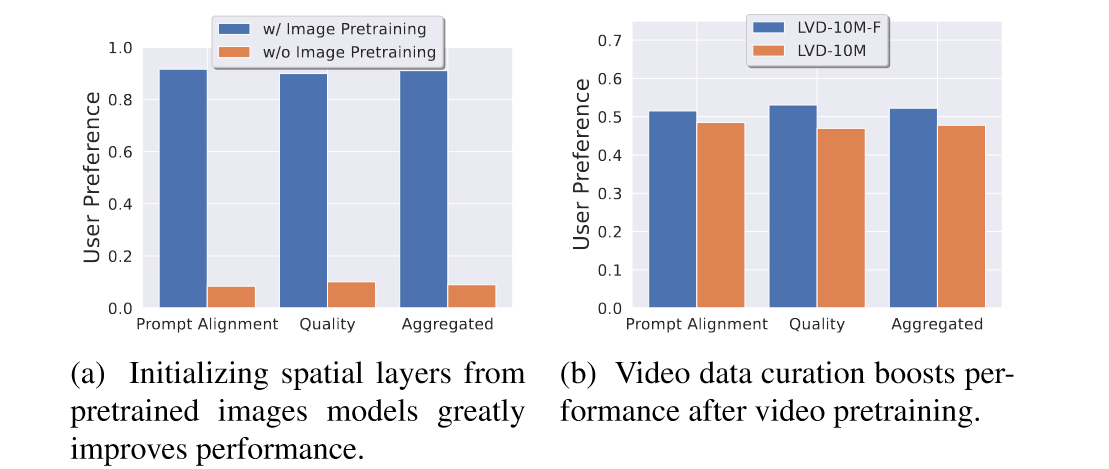
(1)Stage I: Image Pretaining. 利用预训练的 stable diffusion 2.1 来初始化 spatial weights。作者比较了没初始化的训练结果,证明权重初始化可以提高 prompt alignment, quality, aggregated 这三个指标。
(2)Stage II: Curating a Video Pretraining Dataset. 清洗 LVD-10M 数据集得到一个四倍小的数据集LVD-10M-F。作者比较了没清洗的数据集上的训练结果,证明 LVD-10M-F 可以提高 prompt alignment, quality, aggregated 这三个指标。
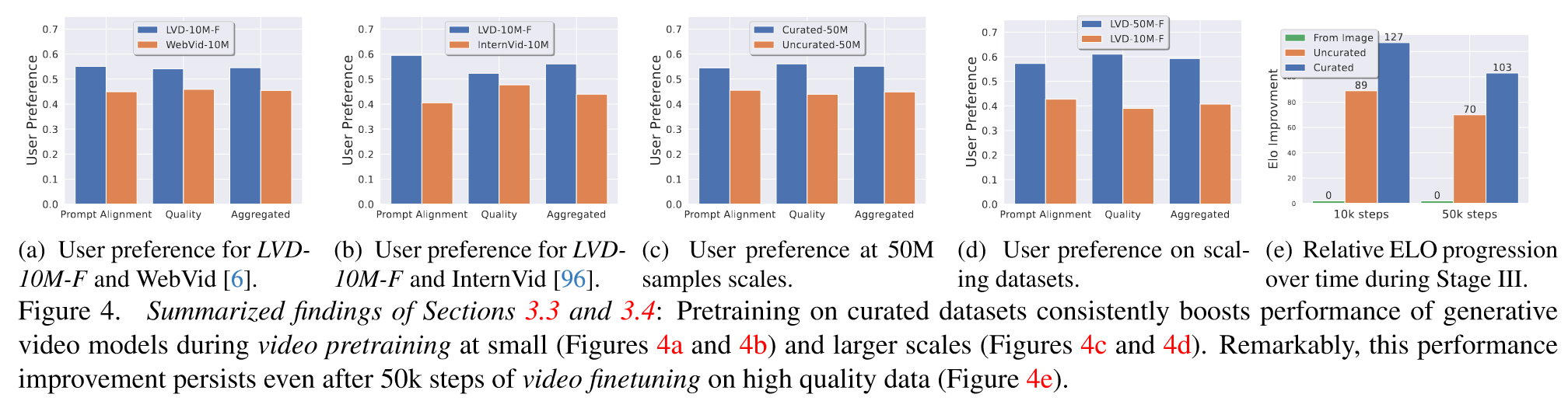
(3)Stage III: High-Quality Finetuning. 用一个包含 250K 个高保真度的 pre-captioned video clips 的小型数据集,对模型进行 50K 步的微调,训练方式类似于 ldm 通过级联扩散模型以提高分辨率。作者针对不同方式训练的初始模型做了消融实验,得出结论: i) 视频预训练和视频微调中视频模型训练的分离有利于微调后的最终模型性能,并且 ii) 视频预训练理想情况下应在大规模、精心策划的数据集上进行,因为预训练后的性能差异在微调后仍然存在。
四、总结
应该是现有的最好的开源text2video方案了。此外还提供了多视图微调方案以完成3D任务。
http://y-ichen.github.io/2023/11/29/2023-11-29%20[Daily%20Trend]%20744dda0cdf6743a39763020f8766e5c9/
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.